




The code referenced by this blog is available on GitHub
Like just about every person with an internet connection, I've fallen victim to the addiction of the Wordle puzzle. But this is the kind of addiction that I like because it takes no more than 5 minutes of your day, and then forces you to wait eagerly for the next day's puzzle.
At least, that is how normal people engage with the puzzle. The more obsessive types will spend some extra time pondering what a good strategy might be for solving the puzzle. They then ponder how that strategy might be turned into an algorithm. And they then set about turning that algorithm into a functioning Wordle solver.
I would be very surprised if there isn't a multitude of Wordle solvers available already. But my interest is not so much in getting the answer to each day's puzzle, but rather to see if I could solve the puzzle programatically. Thus it began...
The Tools
My first choice for writing a simple logic app like this would have been Go. I might also have done it in C++ or C#. But I decided against. At it's core, this solver will be matching strings from a big file using Regular Expressions. This is something I find myself doing on a regular basis when trawling through log files for certain patterns or anomalies. I am reasonably well versed in the syntax and use of Regular Expressions but I am often frustrated by the syntax of grep or sed, the Linux command line tools with which I normally use regexes. As such, I decided that this might be a good opportunity to take those head on and get some exercise on grep, sed and regex syntax while solving this puzzle.
The Algorithm
The algorithm involves a simple iteration, starting with an opening guess, constructing regexes based on the result of that guess (and previous results), and then choosing a new guess from a list of words. How do we construct these regexes then? Essentially, there are four regexes that can be inferred from the result. Let's imagine the first guess resulted in the following answer:

1. Valid letters
When a word is guessed, the response tells us which letters are correct but in the incorrect position (ORANGE) and which letters are correct and in the correct position (GREEN). This means that we can already limit any future guesses to words that, at the very least, contain those letters. Any word which does not contain any of these letters is obviously not a candidate and can be eliminated. Of the four, this is perhaps the trickiest of regular expressions as it requires positive lookahead. In the example above, there are only two letters which we know are correct (whether or not they are in the correct position). A regex which matches all words that contain those two letters might look as follows:
^(?=.*d)(?=.*e).*$
And here's a graphical explanation of what the above regex does

Note: One might also want to include in the regex the assertion that the matching word should be exactly 5 letters long. This would be easy enough but is achieved through using a base list consisting only of 5 letter words. Also, the 3rd and 4th regeg below implicitly includes that assertion.
2. Invalid letters
All the incorrect letters from the response (GREY) tells us that no word containing any of those should be considered for future guesses. In the example above, there are three letters which are incorrect. A regex which matches all words that do not contain those letters is expressed simply as:
^[^aiu]+$
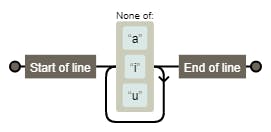
3. Positionally correct letters
Letters that are correct and also in the correct position (GREEN) can help us limit future guesses to only the words containing those letters in those positions.
^.{3}e.$

For simplicity of constructing the regex, we're not using those repetition curly braces though but rather express each character in the word as either a dot (unknown) or a letter (known).
^...e.$
4. Positionally incorrect letters
Finally, there are letters which we know are incorrect for the position they appear in. These might even be letters that are correct elsewhere in the word but we know that they don't appear in a specific position and so we can limit future guesses to words that do not contain those letters in those positions. A regex for this step from the example above might look like this:
^[^a][^d][^i].[^u]$

*Note: This regex might very easily have been combined with the previous regex into one single regex. As a matter of fact, there's no reason why all four regexes couldn't be combined into a single regex but or ease of construction and readability, we're keeping them separate though.
So once these four regexes have been constructed, we can apply them all to the source list and obtain a new, smaller list to choose our next word from.
It is important to note here that these regexes might seem very simple at this point but they will get more complex with subsequent guesses. Each guess adds more information to each position in the word, telling us which letters to include in the four different regexes. For instance, if the second guess resulted in the following answer:

the new set of regexes might look as follows:
regex 1:
^(?=.*d)(?=.*e)(?=.*t).*$
 (One new valid letter (t) identified)
(One new valid letter (t) identified)
Note: this algorithm lacks an elegant way to deal with the case where one letter appears twice in the word
regex 2:
^[^aisu]+$
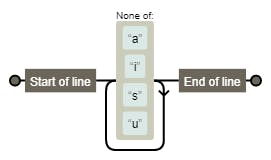 (one new invalid letter (s) identified)
(one new invalid letter (s) identified)
regex 3:
^..eed$
 (two new positionally correct letters identified)
(two new positionally correct letters identified)
regex 4:
^.[^dt]...$
 (one new positionally incorrect letter identified for the second position)
(one new positionally incorrect letter identified for the second position)
With each iteration of this loop the base list gets whittled down pretty rapidly.
Algorithm Diagram
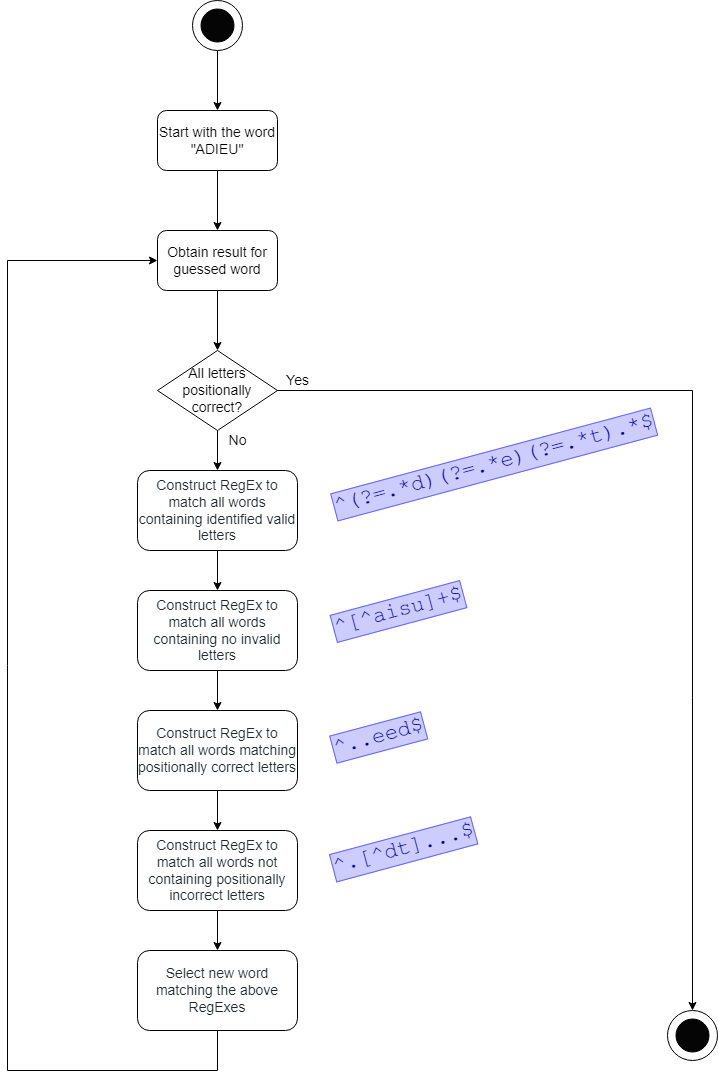
The Bash Script
The entire bash script performing this procedure is available for scrutiny on GitHub and is commented, but below are some of the salient points.
The script starts with an initial guess of "ADIEU". This is just a word that has been chosen as a supposed decent first guess. It contains four vowels and a very common consonant. The theory is that this guess will immediately identify at least some positive matches or disqualify a large number of words from the base list outright.
The user is required to provide feedback of the result from the Wordle puzzle in the form of 5 characters, a combination of the following: + correct letter, correct position (green) - correct letter, incorrect position (orange) x incorrect letter
From here, the script will whittle down the base list by applying the regexes discussed above. It is still fairly crude in how it selects the next guess for the puzzle. In fact, it simply picks the first word from the remaining candidates, but offers the user the option to disregard that choice and to go with the next one. This script could definitely be improved by implementing a better mechanism for choosing the next word from the list of remaining candidates. A good approach might be to pick the next word such that the new letters it contains are also contained in as many other words from the list as possible.
One a new word is selected, the script awaits feedback from the user so that it can expand on its regular expressions and repeat the process.
The Base List
Of course the quality of the guesses is a direct function of the quality of the base list of words. Two lists of English words that I was able to find can be obtained from https://github.com/first20hours/google-10000-english and https://github.com/dwyl/english-words. Unfortunately both of these word lists have their shortcomings nd produce varying results.
However, at some point I discovered that the entire word list used by Wordle, all 12 971 of them, is visible right there in the source code and so I extracted those and saved it to a file, called wordlewords.txt which I included in the respository. This is of course next level cheating but then, let's be honest, this entire exercise was an exercise in cheating. So we're well beyond the point of choosing the best morally defensible route 😊